干货 | 数据挖掘技术在风控领域的典型应用
2018-05-08 00:56 6850

数据挖掘(data mining)是采用统计、数学、人工智能和神经网络等领域的科学方法,如记忆推理、聚类分析、关联分析、决策树、神经网络、基因算法等技术,从大量数据中挖掘出隐含的、先前未知的、对决策有潜在价值的关系、模式和趋势,并用这些知识和规则建立用于决策支持的模型,提供预测性决策支持的方法、工具和过程。
数据挖掘技术是统计技术、计算机技术和人工智能技术等构成的一种新学科。数据挖掘来源于统计分析,是统计分析方法的扩展和延伸。大多数的统计分析技术都基于完善的数学理论和高超的技巧,其预测的准确程度还是令人满意的,但对于使用者的知识要求比较高。
而随着计算机能力的不断发展,数据挖掘可以利用相对简单和固定程序完成同样的功能。新的计算算法的产生如神经网络、决策树使人们不需了解到其内部复杂的原理也可以通过这些方法获得良好的分析和预测效果。
数据挖掘方法
数据挖掘技术是数据库技术、统计技术和人工智能技术发展的产物。从使用的技术角度,主要的数据挖掘方法包括:
决策树方法:利用树形结构来表示决策集合,这些决策集合通过对数据集的分类产生规则。国际上最有影响和最早的决策树方法是ID3方法,后来又发展了其它的决策树方法。
规则归纳方法:通过统计方法归纳,提取有价值的if-then规则。规则归纳技术在数据挖掘中被广泛使用,其中以关联规则挖掘的研究开展得较为积极和深入。
神经网络方法:从结构上模拟生物神经网络,以模型和学习规则为基础,建立3种神经网络模型:前馈式网络、反馈式网络和自组织网络。这种方法通过训练来学习的非线性预测模型,可以完成分类、聚类和特征挖掘等多种数据挖掘任务。
遗传算法:模拟生物进化过程的算法,由繁殖(选择)、交叉(重组)、变异(突变)三个基本算子组成。为了应用遗传算法,需要将数据挖掘任务表达为一种搜索问题,从而发挥遗传算法的优化搜索能力。
粗糙集(RoughSet)方法:Rough集理论是由波兰数学家Pawlak在八十年代初提出的一种处理模糊和不精确性问题的新型数学工具。它特别适合于数据简化,数据相关性的发现,发现数据意义,发现数据的相似或差别,发现数据模式和数据的近似分类等,近年来已被成功地应用在数据挖掘和知识发现研究领域中。
K2最邻近技术:这种技术通过K个最相近的历史记录的组合来辨别新的记录。这种技术可以作为聚类和偏差分析等挖掘任务。
可视化技术:将信息模式、数据的关联或趋势等以直观的图形方式表示,决策者可以通过可视化技术交互地分析数据关系。可视化数据分析技术拓宽了传统的图表功能,使用户对数据的剖析更清楚。
数据挖掘功能
数据挖掘综合了各个学科技术,有很多的功能,当前的主要功能如下:
分类:按照分析对象的属性、特征,建立不同的组类来描述事物。例如:银行部门根据以前的数据将客户分成了不同的类别,现在就可以根据这些来区分新申请贷款的客户,以采取相应的贷款方案。
聚类:识别出分析对内在的规则,按照这些规则把对象分成若干类。例如:将申请人分为高度风险申请者,中度风险申请者,低度风险申请者。
关联规则:关联是某种事物发生时其他事物会发生的这样一种联系。例如:每天购买啤酒的人也有可能购买香烟,比重有多大,可以通过关联的支持度和可信度来描述。
预测:把握分析对象发展的规律,对未来的趋势做出预见。例如:对未来经济发展的判断。
偏差的检测:对分析对象的少数的、极端的特例的描述,揭示内在的原因。例如:在银行的100万笔交易中有500例的欺诈行为,银行为了稳健经营,就要发现这500例的内在因素,减小以后经营的风险。
数据挖掘经典算法
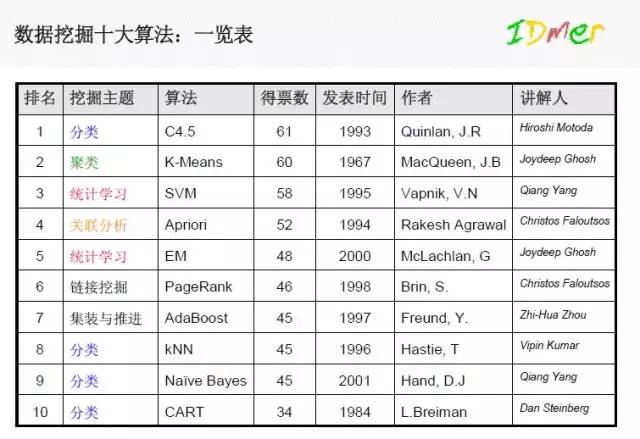
C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法. C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
1) 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2) 在树构造过程中进行剪枝;
3) 能够完成对连续属性的离散化处理;
4) 能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
The k-means algorithm 即K-Means算法
k-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割,k < n。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。
Support vector machines
支持向量机,英文为Support Vector Machine,简称SV机(论文中一般简称SVM)。它是一种監督式學習的方法,它广泛的应用于统计分类以及回归分析中。支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。一个极好的指南是C.J.C Burges的《模式识别支持向量机指南》。van der Walt 和 Barnard 将支持向量机和其他分类器进行了比较。
The Apriori algorithm
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
最大期望(EM)算法
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variabl)。最大期望经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。
PageRank
PageRank是Google算法的重要内容。2001年9月被授予美国专利,专利人是Google创始人之一拉里·佩奇(Larry Page)。因此,PageRank里的page不是指网页,而是指佩奇,即这个等级方法是以佩奇来命名的。
PageRank根据网站的外部链接和内部链接的数量和质量俩衡量网站的价值。PageRank背后的概念是,每个到页面的链接都是对该页面的一次投票,被链接的越多,就意味着被其他网站投票越多。这个就是所谓的“链接流行度”——衡量多少人愿意将他们的网站和你的网站挂钩。PageRank这个概念引自学术中一篇论文的被引述的频度——即被别人引述的次数越多,一般判断这篇论文的权威性就越高。
AdaBoost
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器 (强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。
kNN: k-nearest neighbor classification
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
Naive Bayes
在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBC)。朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好。
CART: 分类与回归树
CART, Classification and Regression Trees。 在分类树下面有两个关键的思想。第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。
数据挖掘在金融风控领域的应用
信贷风险评估
在传统方法中,银行对企业客户的违约风险评估多是基于过往的信贷数据和交易数据等静态数据,这种方式的最大弊端就是缺少前瞻性。而数据挖掘手段的介入使信贷风险评估更趋近于事实,信贷风险评估步骤如下:
(1)以客户级数据为基础,为存量客户建立画像,使银行能够向各管辖机构、各业务条线、各产品条线进行内容全面、形式友好、敏捷的客户级大数据集中供给。
(2)建立专项集中的企业及个人风险名单库,统一“风险客户”等级标准,集中支持各专业条线、各金融产品对高风险客户的过滤工作。
(3)统筹各专业条线、各业务环节对数据增量信息的需求优先序列,对新客户、高等级客户、高时效业务、高风险业务实现大数据实时采集式更新对存量、一般、普通时效业务、低风险业务实现数据集中、批量、排序、滚动更新。
交易欺诈识别
目前,支付服务操作十分便捷,客户已经可以做到随时、随地进行转账操作。面对盗刷和金融诈骗案件频发的现状,支付清算企业交易诈骗识别挑战巨大。
数据挖掘可以利用账户基本信息、交易历史、位置历史、历史行为模式、正在发生行为模式等,结合智能规则引擎进行实时的交易反欺诈分析。整个技术实现流程为实时采集行为日志、实时计算行为特征、实时判断欺诈等级、实时触发风控决策、案件归并形成闭环。

黑产防范
互联网金融企业追求服务体验,强调便捷高效,简化手续,而这一特点也易被不法分子利用,虚假注册、利用网络购买的身份信息与银行卡进行套现,“多头借贷”乃至开发电脑程序骗取贷款等已经形成了一条“黑色”产业链,对于互联网金融行业而言,欺诈风险高于信用风险。
数据挖掘能够帮助企业掌握互联网金融黑产的行为特点、从业人员规模、团伙地域化分布以及专业化工具等情况,如借款手机归属地与真实城市IP不匹配,设备上相邻两次借款(含跨平台)时间间隔极短,用户手机长期处于同一位置未移动过等。通过黑产识别和预警制定针对性的策略,减少损失。
消费信贷
消费信贷和传统企业信贷截然不同,拥有小额、分散、高频、无抵押和利息跨度极大的特点。客户特点是年轻、消费观念超前、无信用记录。
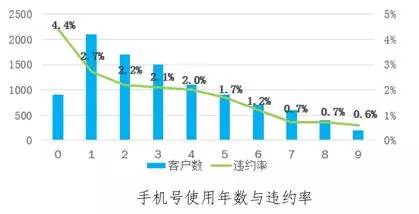
数据需要贯穿到客户全生命周期的始末,基于大数据的自动评分模型、自动审批系统和催收系统是消费信贷的基础,利用大量行为数据分析弥补信贷数据的缺失。一些趋势上的分析方法如:随着手机号使用年数的增加,客户稳定性增加,违约风险逐步降低;过去12个月内所有类目本地生活消费等级越高,违约风险越低;最近12个月网络游戏消费金额越多,违约风险越高;最近12个月内财经媒体访问天数越多,违约率风险越低,等等。
数据挖掘作为深层次的数据信息分析方法,具有传统评价方法无法具备的对于各种因素之间隐藏的内在联系的全面分析。此技术应用于金融风险管理无疑非常有益,可提供风险预警,让管理者提前做好准备,为决策提供参考信息,因而使企业极大地降低风险和提高竞争力,为企业的长足发展作出贡献。
申明:感谢作者的辛勤原创!若在本网站转发过程中涉及到版权问题,敬请与管理员联系!以便及时更改删除,谢谢!
另:法财库目前成立了多个行业微信群【银行高管群】【商业银行群】【信托群】【券商群】【理财师群】【投行群】【私募群】【基金群】【股权投资群】【期货群】【现金贷】【第三方支付】【金融高管群】【总裁群】【互联网高管群】【汽车金融群】【融资租赁群】
扫码加群主申请入群

1. 干货 |信贷风控领域风控策略解读
2. 十大维度揭秘中國经济的真相,字字珠玑!
3. 【江苏银行与南京银行】一省双雄会:城商行第3与第5的家底大比拼
4. 李奇霖:如何理解大额风险暴露新规?
5. 从资管到投行:银行战略转型新蓝海
6. 腾讯的梦想,你看清了么?
7. 上市券商2017年报业绩纵览,可以这么看
8. 详解清华系、海航系、复星系的超级产业投资模式!(深度好文!)
9. 中美贸易谈判路径推演:谁来谈?谈什么?
10. 一图看懂上市银行2017年报业绩、资产、薪酬情况